

Forensic voice analysis for mediumistic phenomena
When skeptics are looking for conventional explanations for mediumistic phenomena they typically claim that the medium himself/herself is somehow faking the spirit voices
(even though mediums like Warren Caylor have their mouth duct taped). Even when the spirit voices sound very different than the voice of the medium,
it remains difficult to argue about subjective similarities and whether a voice could be imitated.
Fortunately, speech processing technology can be used to provide evidence beyond subjective judgements; and in addition it can take into account
speech features which are hardly audible, because they do not matter in normal speech understanding.
Here is some information on the investigations and results of forensic voice comparison (which is the common term in this field of research) done with audio recordings of séances with Warren Caylor. Many thanks to Warren and his spirit team for supporting this work!
NOTE: This is work in progress, results and descriptions on this Web page are still preliminary. The last section will give some information on what should be done in the future to provide more robust data.
Here is some information on the investigations and results of forensic voice comparison (which is the common term in this field of research) done with audio recordings of séances with Warren Caylor. Many thanks to Warren and his spirit team for supporting this work!
NOTE: This is work in progress, results and descriptions on this Web page are still preliminary. The last section will give some information on what should be done in the future to provide more robust data.
Introduction: Forensic voice comparison for mediumistic phenomena
The typical task in forensic voice comparison is to analyse and compare speech samples in order to decide whether a suspect is identical with the offender.
By comparing the voice samples with each other but also with other voices, a likelihood ratio is calculated: What is the probablity that suspect and offender voice are the same versus
the probablity that the offender voice can come from somebody else.
To provide evidence for or against the originality / authenticity of mediumistic spirit voices, this approach has to be adapted somewhat. Especially, it has to take into account that a medium trying to fake a spirit voice will probably not use his own natural voice but will try to feign a voice which sounds different. For example, it is quite easy to shift the pitch of the voice to sound differently. Thus the pitch (technical term: the fundamental frequency) of the voice will typically only provide very weak evidence. Of much more interest are some overtones in the voice, the so-called formants, which depend on the vocal tract - its anatomical shape as well as (mostly unconscious) patterns how it is changing with the tongue, mouth, oral and nasal cavities when speaking. In contrast to forensic voice comparison, which often has to rely on low-quality audio recordings, such as from telephone communication, séance phenomena can be recorded with high-quality audio, thus also making the higher formants, especially F3, F4, available for analysis.
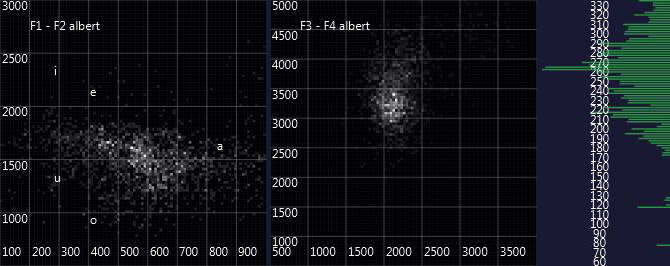
The following picture gives an example (spirit voice Albert). On the left hand side, it shows how often formant F1 and formant F2 appear in a certain relation to each other. The F1-F2-combination is the main factor to distinguish between the sound of different vowels (rough average positions of some vowels are indicated), but it also depends on the individual speaker. In the middle, the picture shows the distribution of the combinations of the formants F3 and F4. They have a higher frequency and do not matter for speech recognition, but can be relevant for distinguishing different speakers.
To provide evidence for or against the originality / authenticity of mediumistic spirit voices, this approach has to be adapted somewhat. Especially, it has to take into account that a medium trying to fake a spirit voice will probably not use his own natural voice but will try to feign a voice which sounds different. For example, it is quite easy to shift the pitch of the voice to sound differently. Thus the pitch (technical term: the fundamental frequency) of the voice will typically only provide very weak evidence. Of much more interest are some overtones in the voice, the so-called formants, which depend on the vocal tract - its anatomical shape as well as (mostly unconscious) patterns how it is changing with the tongue, mouth, oral and nasal cavities when speaking. In contrast to forensic voice comparison, which often has to rely on low-quality audio recordings, such as from telephone communication, séance phenomena can be recorded with high-quality audio, thus also making the higher formants, especially F3, F4, available for analysis.
The following picture gives an example (spirit voice Albert). On the left hand side, it shows how often formant F1 and formant F2 appear in a certain relation to each other. The F1-F2-combination is the main factor to distinguish between the sound of different vowels (rough average positions of some vowels are indicated), but it also depends on the individual speaker. In the middle, the picture shows the distribution of the combinations of the formants F3 and F4. They have a higher frequency and do not matter for speech recognition, but can be relevant for distinguishing different speakers.
Can the medium fake all those different spirit voices?
A first question to address skeptics is: How likely is it
that the medium is capable to fake the various spirit voices heard during a séance - taking into account that the medium purposely may try to force his own voice to sound different.
Here are the graphs of some other spirit voices appearing in Warren's séances:
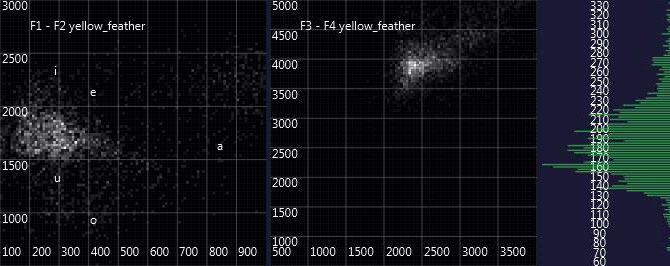
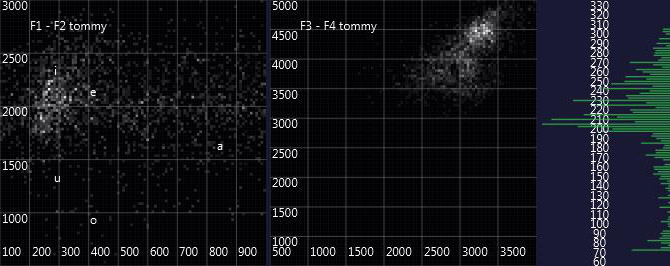
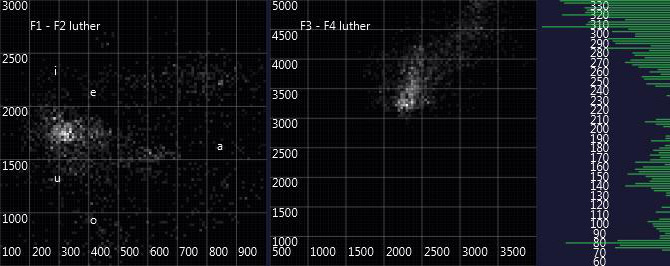
Already the visual appearance shows a lot of differences. (For those who know Luther's very low voice: The very high fundamental frequencies in the diagram are a problem of the pitch detection algorithm when dealing with Luther's special, mostly unvoiced pronunciation, which may as well be somewhat below the detection pitch range).
To further illustrate the different profiles of the spirit voices and Warren Caylor's own voice, here the F3-F4-distributions are shown in a single 3D view:

Here are the graphs of some other spirit voices appearing in Warren's séances:
Already the visual appearance shows a lot of differences. (For those who know Luther's very low voice: The very high fundamental frequencies in the diagram are a problem of the pitch detection algorithm when dealing with Luther's special, mostly unvoiced pronunciation, which may as well be somewhat below the detection pitch range).
To further illustrate the different profiles of the spirit voices and Warren Caylor's own voice, here the F3-F4-distributions are shown in a single 3D view:
Comparison: A professional artist working with his voice
In order to judge the differences between the spirit voices, a key question is how far a speaker (e.g. the medium) can force his force to sound differently.
To investigate this question, I took the recording of a professional (and by the way, really brilliant) comedian who is having a dialogue between himself and (amongst others)
a kangaroo, which he represents by very markedly changing his voice. (Marc-Uwe Kling - Die Känguru-Chroniken)
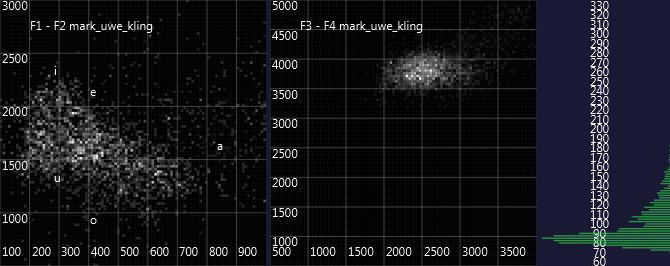
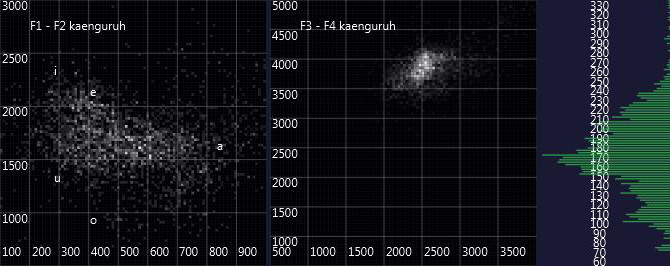
Apparently, the voice profiles are quite similar, even though Marc-Uwe Kling is a very experienced performer and produces voices which sound very different (which in the diagram at least can be seen in the very different fundamental frequencies). Especially the F3/F4 formants are located at almost the same frequencies.
Here, for further illustration also the 3D view of the data:

Of course, further measurements and objective distance metrics are required to provide better evidence. But these first, preliminary results clearly indicate that the different voices to be heard at Warren's séances are much more different than what even a professional actor might produce with his own voice (and remember: the actor does not have a duct tape on his mouth).
Apparently, the voice profiles are quite similar, even though Marc-Uwe Kling is a very experienced performer and produces voices which sound very different (which in the diagram at least can be seen in the very different fundamental frequencies). Especially the F3/F4 formants are located at almost the same frequencies.
Here, for further illustration also the 3D view of the data:
Of course, further measurements and objective distance metrics are required to provide better evidence. But these first, preliminary results clearly indicate that the different voices to be heard at Warren's séances are much more different than what even a professional actor might produce with his own voice (and remember: the actor does not have a duct tape on his mouth).
Spirit voices and real-life personalities
An additional interesting question arises when persons are coming through as spirit voices from whom audio recordings are available, made during their lifetime.
Fortunately, the appearance of Winston Churchill in Warren's séances provide a great research opportunity also for these types of mediumistic phenomena.
In these cases, four or more different voices can be of interest for the analysis:
So, here are some first charts. The first one is the Spirit voice of 'Winston' in Warren's séances, the second the original voice of Winston Churchill from the Youtube-Video 'We shall fight on the beaches' and the last one the actor Albert Finney playing Winston Churchill in 'The Gathering Storm':
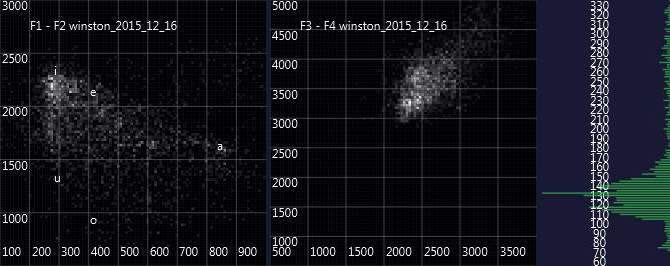
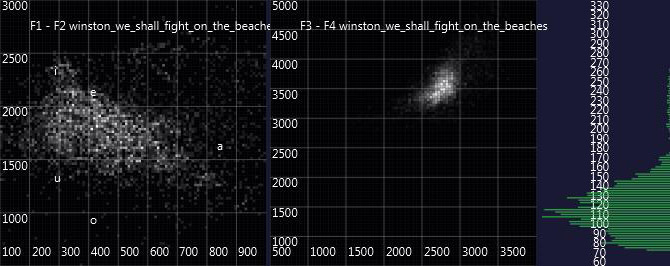
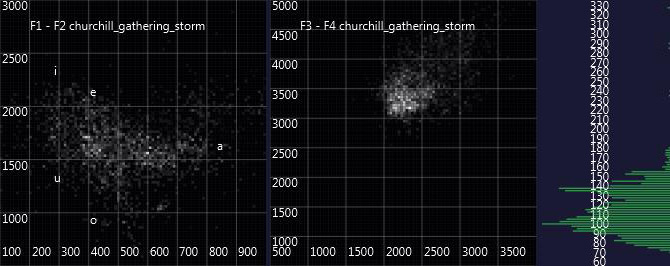
The comparison faces the problem that the audio samples are coming from different sources and the original Churchill recording has low quality and lots of noise, so it has to be investigated how this might impact the formant charts. Also, it needs to be investigated how Churchill's voice has changed throughout his lifetime. Maybe the spirit voice resembles more a younger or (as Lucius Werthmüller from Basle Psi association has suggested:) an older Churchill. In addition, the current audio recording of the spirit voice is quite short (also resulting in the rather faint parts of the formant charts), so definitely, more data is needed. Still, from the very first impression, one might say that the spirit voice seems to come at least as close to the original Churchill as the highly acclaimed actor Albert Finney 'imitating' Churchill in a professional TV production, where he could practice every line in advance - while the spirit voices are typically having interactive, spontaneous conversations with the séance participants.
In these cases, four or more different voices can be of interest for the analysis:
- The original voice of the trance medium
- The spirit voice during the séance
- Original recordings of the 'real-life'/historic person during his/her lifetime - maybe even at different ages, as the voice might change over the course of the years
- Other people such as actors trying to imitate the voice of the personality
So, here are some first charts. The first one is the Spirit voice of 'Winston' in Warren's séances, the second the original voice of Winston Churchill from the Youtube-Video 'We shall fight on the beaches' and the last one the actor Albert Finney playing Winston Churchill in 'The Gathering Storm':
The comparison faces the problem that the audio samples are coming from different sources and the original Churchill recording has low quality and lots of noise, so it has to be investigated how this might impact the formant charts. Also, it needs to be investigated how Churchill's voice has changed throughout his lifetime. Maybe the spirit voice resembles more a younger or (as Lucius Werthmüller from Basle Psi association has suggested:) an older Churchill. In addition, the current audio recording of the spirit voice is quite short (also resulting in the rather faint parts of the formant charts), so definitely, more data is needed. Still, from the very first impression, one might say that the spirit voice seems to come at least as close to the original Churchill as the highly acclaimed actor Albert Finney 'imitating' Churchill in a professional TV production, where he could practice every line in advance - while the spirit voices are typically having interactive, spontaneous conversations with the séance participants.
Notes and potential next steps
Please note that these are all preliminary results. Further work is needed to (hopefully) get more robust evidence. Some potential next steps:
- Calculate objective metrics to measure the distance/difference between the different formant charts, ideally something similar to the likelihood ratio, which is the current best practice in forensic voice comparison.
- Collect more data, including Warren's own voice as reference.
- Regarding the Churchill charts, the different audio quality (especially the poor quality of the historic recordings) might have some impact on the results, which still needs to be investigated. (The séance recordings have all been done with the same, high-quality recording settings)
- Marc-Uwe Kling and his kangaroo was just one example of the potential impact of faking a voice. Further examples would be good to harden this type of evidence.
- Formant trajectories (especially F1-F2) could provide further evidence for speaker identification, but this requires some more tedious work, especially the (manual) selection of certain diphthongs and monophthongs from the audio tracks.
- The formant analysis has been done automatically with the very popular speech processing software Praat, with some post-processing in my own software to create the correlation charts and to remove formant outliers (e.g. when Praat does not correctly detect F1 it outputs F2 as F1, F3 as F2 etc.), ideally, for more precise results, the automated formant output of Praat should be checked and/or fine-tuned visually/manually (tedious work...).
References
- Geoffrey Stewart Morrison, Vowel inherent spectral change in forensic voice comparison, in Vowel Inherent Spectral Change, edited by G. S. Morrison and P. F. Assmann, Springer, 2013
- Jacob Benesty, Jingdong Chen, Yiteng Huang (Eds.): Springer Handbook of Speech Processing, Springer, 2008